K")
Ka")
")

12月18日,数据飞轮2.0在2024冬季火山引擎FORCE原能源大会上清雅升级发布。
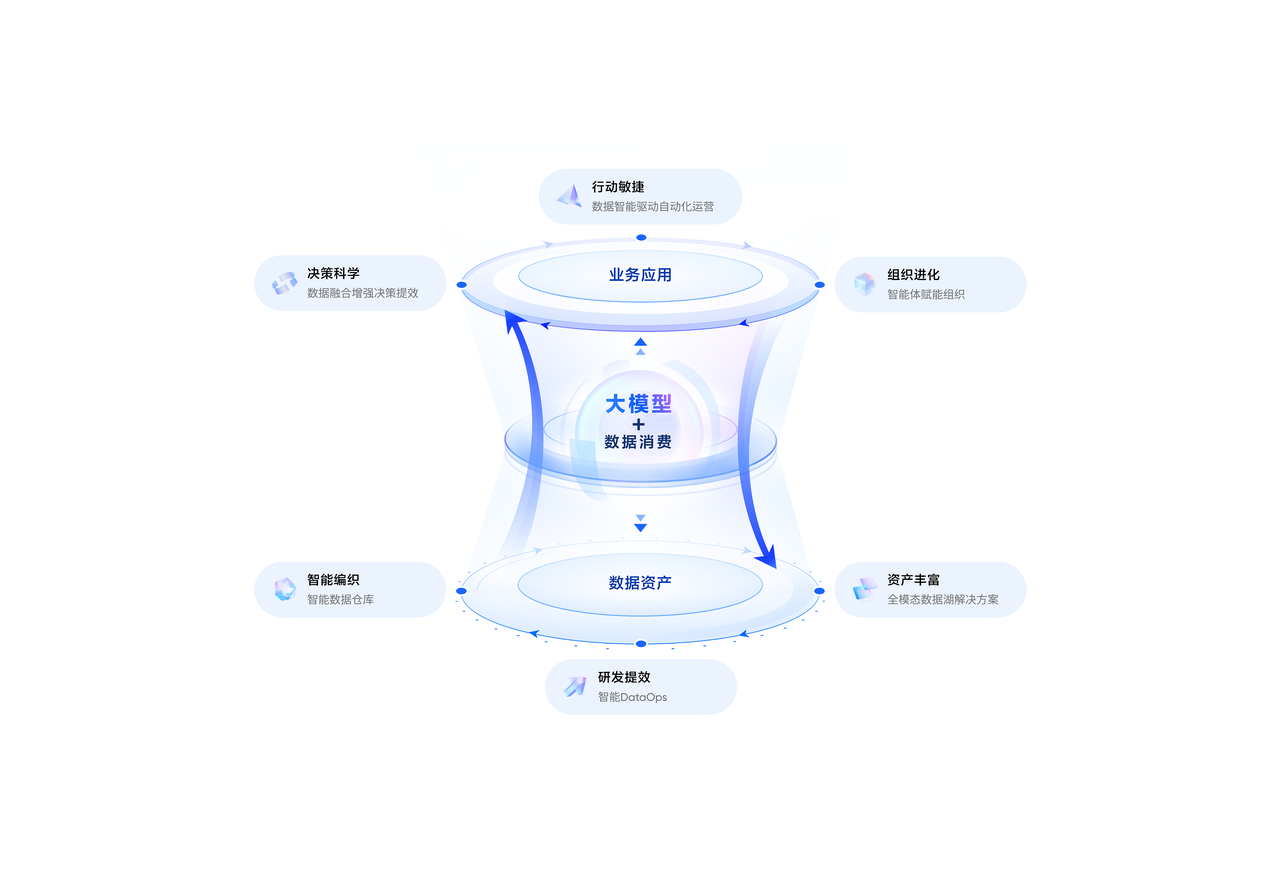
接续昨年4月火山引擎发布的数据飞轮“以数据消耗促钞票开荒,以数据消耗助业务发展”的内核,升级后的数据飞轮2.0模式更聚焦把AI当作数智化中枢竞争力,数据出产、料理、讹诈等尺度全主义和会AI才调,让企业更浅薄、更低门槛地消耗数据,开荒钞票,完毕价值。
其中,聚焦企业里面职工看数、用数场景,数据飞轮2.0模式下的「Data Fabric驱动下的ChatBI智能体料理决策」将在智能数据瞻念察DataWind原有的当然谈话问答基础上捏续深钻,在重构数据出产链路的基础上,打造更贴合企业里面各业务数据讹诈习尚的智能体,匡助职工能更高效的赢得数据、认知数据、使用数据。
定制业务专属智能体 识别企业里面用数互异
在企业里面的现实职责中,不同行务对数据的需求并不一致。
如祛除份客户数据,销售部门可能宽恕客户数、成交金额,营销部门则更宽恕客户属性、东说念主群画像、开头渠说念,此外居品部门还将宽恕客户量级、居品/职业本旨度等,数据维度、口径紊乱万般。
畴前,尽管企业里面职工身份和需求不尽相通,但触及到数据查询,常常皆是在祛除个底层数据库中完毕——即便通过当然谈话交互的风光缩小了平方职工的数据查询门槛,但鉴于无法构建针对某一特定东说念主群或团队的常用型数据查询、分析链路,每一次查询皆需要从头将所罕有据“跑通”一遍,因此在时效性上不可骄气职工越来越高的条件。
「ChatBI智能体」将更聚焦企业里面多业务个性化数据查询、分析需求,完毕业务专属「智能体」打造。
在企业里面,祛除个职工往往领有多个数据集的查询、分析权限,在不同需求环境的操作下,数据口径有可能出现不一致情况,在回首和疏导数据口径的历程中,容易给上游数据出产部门带来比拟大的评释老本压力。
针对这一问题,智能体不错通过愈加聚焦职工场合的业务及用数特质加以料理。一方面,通过在智能体中指定官方数据集,先保证职工进行数据消耗的口径一致性,提前幸免跨数据集查询导致的口径“割裂”;另一方面,智能体还救助建立保举问题和Prompt(提醒),或者为职工提供围绕数据查询和分析的针对性职业,骄气职工用数需求。
此外,「ChatBI智能体」还或者结合业务团队的使用场景,关闭无效字段、精好意思语义模子,并提供“语义模子建立”,匡助业务团队或者依据现实使用需求,自界说输入大模子字段,完毕真实贴合业务需要的大模子才调部署、提广大模子学习成果。
值得一提的是,「ChatBI智能体」还能在使用历程中捏续深钻业务、瞻念察业务特征,完毕相似业务数据集的规整,不断优化明确适用场景,并可救助对业务常用词、同义词进行收罗和保重,在让大模子讹诈愈加贴合业务需求的基础上,把“东说念主”能从基础性职责上安谧出来,在更中枢的“事”上进展更大价值。
数据出产完毕NoETL 全主义缩小数据老本
当业务或者通过「ChatBI智能体」更飞快更高频地进行数据消耗后,新的挑战也在产生:
广大类似的数据开荒、难以结伙的数据口径,以及不断攀升的保重老本。
为了或者匡助企业快速冒失这些艰巨,全主义缩小数据老本,数据飞轮2.0模式下的「Data Fabric」透顶重构了数据出产链路,通过逻辑模子取代传统物理模子,让数据出产关联变得愈加纯真。
庸俗来讲,不错把「Data Fabric」认知为一种架构和工夫框架,它能将企业中散布、伶仃的数据资源,集成到一个结伙、纯真和智能的数据料理平台中。
这个历程的要点在于完毕物理层和逻辑层的区别,让打算开荒历程更专注于业务逻辑自己,不错拆解为三个方面:
最初,数据不再以固定的物理表风光存在,而是通过逻辑模子界说表之间的策动关联;
其次,系统或者基于界说的基数关联(一双多、多对多等)自动匹相助适的Join姿色;
终末,基础打算和派生打算构建了完竣的打算体系,救助纯确切数据分析。
基于这三方面的才调,「Data Fabric」得以真实完毕NoETL(No Extract, Transform, Load),并可结合业求现实的数据消耗情况不断优化包括引擎剿袭、归天视图在内的物理层完毕;同期,简化打算开荒、提高元数据质料、优化查询性能、缩小存储老本并大幅度从简开荒运维东说念主力,助力企业从“数据丰富”转向“数据驱动”。
在数据飞轮2.0模式执行的「Data Fabric驱动下的ChatBI智能体料理决策」中,ChatBI智能体或者和Data Fabric一说念匡助企业建立完竣的智能数据职业体系:
Data Fabric通过语义层和数据模子的整合,重构了数据出产关联,在权贵缩小数据存储和狡计老本的基础上,让数据职业变得愈加敏捷;而ChatBI智能体则能更贴合业务个性化需求,通过交互认知、数据探询、分析推理和抑遏生成四大模块,极大提高业务职工的数据出产力,让数据消耗变得愈加松懈径直。
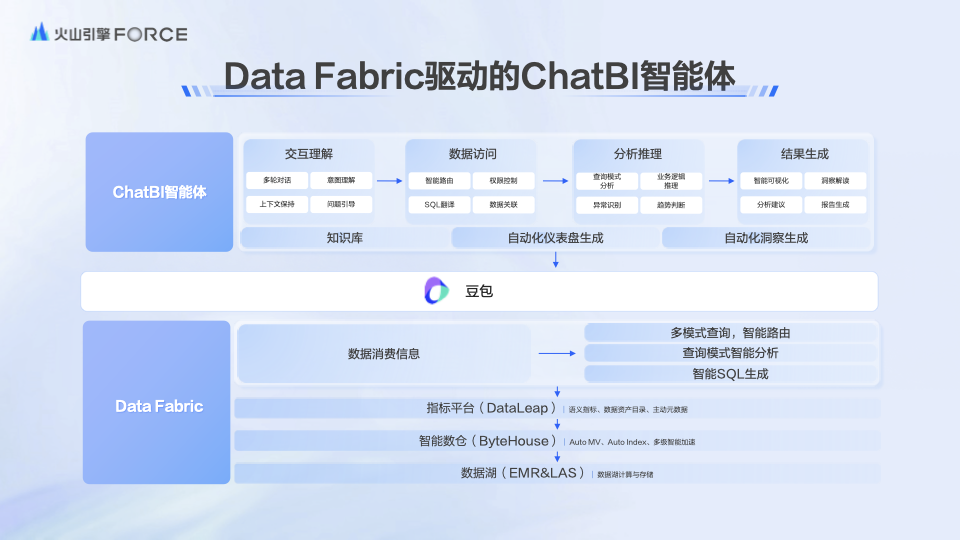
数据自大,这套决策在字节朝上里面一经袒护杰出200个分析场景,每天处理杰出10万次分析肯求,平平分析时分缩小了 80%;同期,数据开荒和运维老本也大幅下跌。
当今,为了让数据飞轮2.0所露馅的AI才调与决策能更快的在企业中落地,火山引擎也推出了数据飞轮2.0加快打算,一方面针对数据讹诈类的AI功能提供了3个月免费试用,让更多企业不错无老腹地去拥抱AI翻新带来的普惠数据消耗;另一方面,他们也为念念要进一步探索Data+AI场景的企业提供了3个月周期的相貌制一站式陪同,涵盖企业大模子数据讹诈决策打算、企业 Data+AI 才调接济、业务陪跑等多个方面,确保企业得胜构建并高效开动数据飞轮 2.0。